how to read nested json files in pyspark?
1. what is Nested json :
basically In the context of data structures, a nested object refers to an object or data structure that is enclosed within another object. It involves organizing data in a hierarchical or nested manner, where one or more data elements are contained within another data element. This concept is common in various programming languages and data formats.
For example, in the context of JSON (JavaScript Object Notation), a nested object is an object that appears as a value for one of the properties of another object. Consider the following JSON snippet:
{
"person": {
"name": "John Doe",
"age": 30,
"address": {
"city": "New York",
"state": "NY"
}
}
}In this example:
- The outer object has a property named “person.”
- The “person” property’s value is another object containing properties like “name,” “age,” and “address.”
- The “address” property itself is an object with properties “city” and “state.”
This hierarchical arrangement, where objects are nested within each other, is what we refer to as a nested object structure.
In programming, working with nested objects often involves accessing or manipulating the nested data using appropriate syntax or methods provided by the programming language or data manipulation tool. In the context of PySpark (as per your previous question), handling nested JSON involves reading and processing JSON data with nested structures in a distributed computing environment.
2. read nested json files in pyspark
Sure, I’ll provide an example of reading a nested JSON file into a PySpark DataFrame. Let’s assume you have a JSON file with nested structures like the following:
[
{
"id": 1,
"name": "John",
"address": {
"city": "New York",
"state": "NY"
},
"phone_numbers": [
{"type": "home", "number": "123-456-7890"},
{"type": "work", "number": "987-654-3210"}
]
},
{
"id": 2,
"name": "Jane",
"address": {
"city": "San Francisco",
"state": "CA"
},
"phone_numbers": [
{"type": "mobile", "number": "555-1234"},
{"type": "work", "number": "777-4321"}
]
}
]Now, let’s read this nested JSON file into a PySpark DataFrame:
from pyspark.sql import SparkSession
# Create a Spark session
spark = SparkSession.builder.appName("NestedJSONExample").getOrCreate()
# Read the nested JSON file
df = spark.read.format("json") \
.option("multiLine", True) \
.option("header",True) \
.option("inferschema",True) \
.load("/path/to/nested.json") \
# Show the content of the DataFrame
df.display(truncate=False)In this example:
- The
addressfield is a nested structure containing thecityandstate. - The
phone_numbersfield is an array of nested structures, where each structure hastypeandnumberfields.
When you run df.display(truncate=False), you should see a DataFrame with nested structures:
+---+----+------------------+----------------------------------+
|id |name|address |phone_numbers |
+---+----+------------------+----------------------------------+
|1 |John|{New York, NY} |[{home, 123-456-7890}, {work, 987-654-3210}]|
|2 |Jane|{San Francisco, CA}|[{mobile, 555-1234}, {work, 777-4321}] |
+---+----+------------------+----------------------------------+3. How to explode nested json file in pyspark
df=spark.read.format("json").option("multiLine", True).load("/schenaris/nested.json")spark.read.format("json") method to read a JSON file. Let's break down the code step by step:
spark.read.format("json"): This part specifies the format of the data you want to read, which is JSON in this case. PySpark supports reading data in various formats, and here you are specifying that the data is in JSON format..option("multiLine", True): This line sets an option for reading JSON files. Specifically, it enables themultiLineoption and sets it toTrue. This is used when your JSON file contains multiple lines for a single record. If your JSON file has records spread across multiple lines, setting this option toTruehelps in reading such multiline JSON files correctly..load("/schenaris/nested.json"): Here, you are loading the JSON data from the specified file path ("/schenaris/nested.json"). Adjust the path accordingly based on the location of your JSON file.
Putting it all together, the code is reading a JSON file with PySpark, handling multiline JSON records, and loading the data into a DataFrame. You can then perform various operations and transformations on this DataFrame using PySpark’s functionalities.
After loading the data into the DataFrame, you might want to perform further operations like filtering, aggregating, or transforming the data. For example:
# Assuming df is the DataFrame loaded from the JSON file
df.display() # Display the first few rows of the DataFrame
df.printSchema() # Print the schema of the DataFrameMake sure to replace df with the actual variable name you assigned to the DataFrame. The display() method is used to display the first few rows of the DataFrame, and printSchema() prints the schema, which shows the data types of each column.
root
|-- batters: struct (nullable = true)
| |-- batter: array (nullable = true)
| | |-- element: struct (containsNull = true)
| | | |-- id: string (nullable = true)
| | | |-- type: string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)
|-- ppu: double (nullable = true)
|-- topping: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- id: string (nullable = true)
| | |-- type: string (nullable = true)
|-- type: string (nullable = true)Remember to adjust the code based on your specific requirements and the structure of your JSON data.
explode :
from pyspark.sql.functions import explode,col #import functions
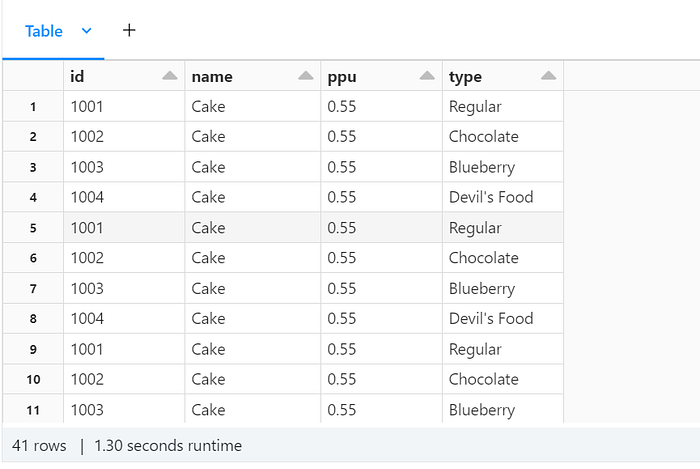
df1 =df.withColumn("topping1", explode("topping")) \
.withColumn("id", col("topping1.id")) \
.withColumn("type", col("topping1.type")) \
.withColumn("topping2", explode("batters.batter")) \
.withColumn("id", col("topping2.id")) \
.withColumn("type", col("topping2.type")) \
.drop("topping1", "topping2", "batters", "topping")
df1.display()Output Dataframe: